- 입력 2022.10.25 13:00
[뉴스웍스=백진호 기자] 국내 연구진이 그래프 신경망모델훈련을 할 때 데이터가 충분치 않아도 예측정확도를 높일 수 있는 새로운 기술을 개발했다.
25일 한국과학기술원(KAIST)에 따르면 박찬영 산업및시스템공학과 교수 연구팀은 데이터가 불충분하고, 데이터 레이블이 없는 상황에서도 예측정확도를 높이는 신규 '그래프 신경망모델훈련 기술'을 발명했다.
데이터 레이블이란 그래프신경망 기술 기반의 서비스를 구축할 때 활용하는 '심층학습'(딥러닝)을 위해 훈련 데이터에 붙이는 정답지이다. 소셜 네트워크의 특정 사용자에 '20대'라는 특성을 부여하면 20대가 레이블이다.
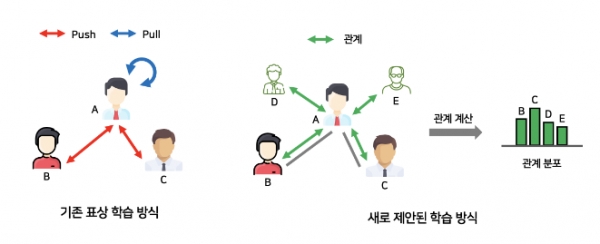
기존 연구에서는 정점의 레이블이 없는 상태에서 이에 대한 표상을 훈련하기 위해 표상 공간 내에서 데이터증강기법으로 하나의 정점에 대한 표현을 만들었다. 이를 제외한 다른 정점들과의 유사도를 축소해 훈련을 진행했다. 결국, 데이터증강기법을 통해 만든 데이터와 관련된 표현에 한해 공통의 특성을 학습하게 된다.
문제는 특정 정점을 제외한 그래프 내의 다른 정점들이 표상 공간에서 멀어지면, 그래프 데이터의 내재적 관계를 학습하기 어렵다는 점이다.
데이터증강기법이란 데이터 부족을 해결하기 위해 데이터를 늘리는 것이다. 최근에는 레이블이 없는 상황에서 하나의 데이터를 기준으로 여러 표현을 만드는 데 쓰이고 있다.
연구팀의 신기술은 그래프신경망 모델에서 정점 간의 관계를 보존해 정점의 레이블이 없는 상황에서도 모델을 훈련시키고, 이를 통해 예측정확도를 증가시킨다. 정점 간의 유사도를 축소하는 훈련과 달리 실제 그래프 상에서 이들이 연관돼 있을 가능성이 있다는 점에 착안했다. 그래프신경망이란 그래프로 표현한 데이터 구조에서 학습하는 심층학습기법이다.
이에 따라 정점 간의 관계를 정의하고 보존해 학습하는 모델을 개발했다. 연구팀은 정점 간의 관계를 기반으로 정점의 표상을 훈련시키고, 기존 연구의 규제를 완화해 그래프 데이터를 모델링했다.
연구팀은 이 학습 방법론을 '관계보존학습'이라고 호칭하고, 그래프 데이터 분석의 주요 문제(정점 분류, 간선 예측)에 적용했다. 그 결과, 최신 연구 방법론과 비교했을 때 정점 분류 문제에서 예측정확도를 최대 3% 높였고, 간선 예측 문제에서는 6%, 다중연결네트워크의 정점 분류 문제에서는 3%의 성능 향상을 이뤄냈다.
박찬영 교수는 "신기술은 그래프 데이터상에 레이블이 부재한 상황에서 표상학습모델을 훈련하는 기존 모델의 단점을 '관계 보존'으로 보완했다"며 "학계에서 큰 파급효과를 낼 수 있다"고 밝혔다.
이번 연구 결과는 국제학술대회 '정보지식관리 콘퍼런스(CIKM) 2022'에서 10월 중 발표될 예정이다.