- 입력 2022.12.05 10:09
[뉴스웍스=백진호 기자] 울산과학기술원(UNIST)은 이정혜 산업공학과 교수팀과 강지훈 고신대복음병원 가정의학과 교수팀이 대규모 한국인 코호트를 기초로 제2형 당뇨 발병 예측 성능을 높인 기계학습(머신러닝) 모델을 개발했다고 5일 발표했다.
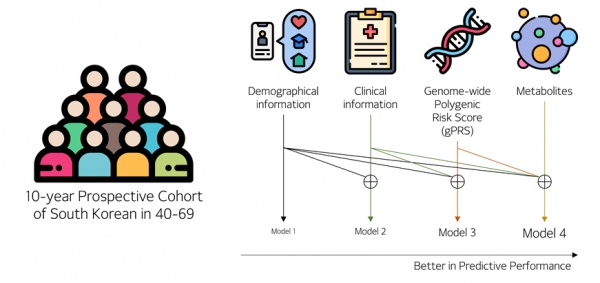
당뇨는 30세 이상의 한국인 6명 중 1명이 앓는 질병인데, 기존의 당뇨 발병 위험예측모델 연구는 주로 서양인 집단을 대상으로 했다. 동양인을 대상으로 해도 키와 몸무게, 가족력 같은 인구통계학적 정보나 당화혈색소(HbA1c) 수치, 콜레스테롤 수치와 같은 임상 정보를 위주로 진행했다. 한국인에 특화된 유전적·환경적 요인까지 반영한 당뇨 예측이 어려울 수밖에 없었다.
연구팀은 한국인에 맞는 예측 모델을 만들기 위해 질병관리본부 국립보건원의 한국인유전체역학조사사업(KoGES) 대규모 코호트를 참고했다. 해당 코호트는 한국인이 흔히 앓는 당뇨, 고혈압, 비만, 대사증후군 등의 만성질환을 연구하기 위해 2001년부터 추적·수집한 자료다.
연구진은 인구통계학적 정보, 임상 정보에 유전 정보와 환경 정보를 더해 종합하면서 당뇨 발병 예측 성능을 높였다. 제1 저자인 한석주 UNIST 산업공학과 박사과정 연구원은 "제2형 당뇨 발병에 관한 유전 정보는 '다유전자 위험 점수'를 한국인 유전자 특성에 맞게 새로 계산해 예측 모델에 활용했다"며 "환경 정보는 '대사체'를 반영해 유전 정보가 설명하지 못하는 정보를 상호보완했다"고 말했다.
최종 발명한 제2형 당뇨발병예측모델은 인구통계학적 정보만 활용한 경우보다 11%포인트 높은 예측 성능을 보였다. 인구통계학적 정보와 임상 정보까지 활용한 경우보다는 4%포인트 향상된 예측 능력을 구현했다.
공동 제1 저자인 김수현 UNIST 산업공학과 박사과정 연구원은 "한국인 대상 코호트에서 인구통계학적 정보와 임상 정보를 얻고, 여기에 새로 개발한 다유전자 위험 점수·대사체 정보를 더할수록 모델의 예측 정확도가 높아졌다"고 강조했다. 이정혜 교수는 "아시아 집단의 코호트 데이터를 이용하는 후속 연구에도 활용될 수 있을 것"이라고 밝혔다.
연구팀은 해당 모델이 한국에게 특화된 당뇨 발병 위험도를 파악하고 발생 요인도 제공할 수 있는 만큼, 임상 현장에서 활용한다면 제2형 당뇨를 효과적으로 예방하고 대응할 수 있을 것으로 기대하고 있다. 연구 결과는 의학 분야 학술지인 란셋의 자매지 '이바이오메디슨'에 공개됐다.